苹果A11深度详解:“仿生”可不是随便说说的
,其实从 A8 开始苹果就基于 Imagination Technologies 的 IP 定制 GPU,被誉为 GPU“心脏”着色器内核以及驱动都是自主完成设计。只不过到了 A11 仿生这一代芯片,苹果才真正公布了完全自主设计的 GPU。
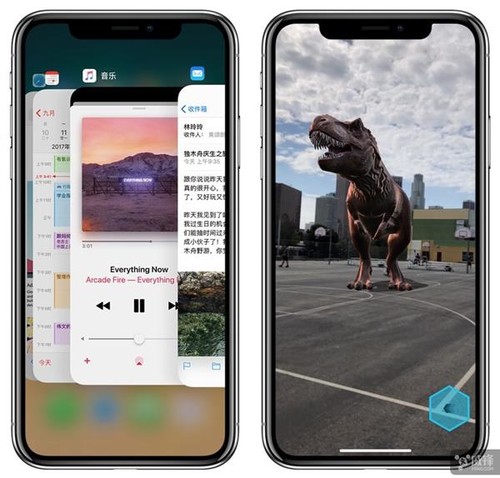
苹果没有透露太多自主设计 GPU 的细节,不过表示 A11 仿生的 GPU 图形处理单元已针对机器学习技术、新颖的沉浸式 3D 游戏和 AR 增强现实体验进行了优化。
其中在 AR 方面苹果称,A11 能发挥六核 CPU 进行全局追踪、场景识别,GPU 图形处理单元还能配合进行惊人的 60 fps 高速处理,同时自主定制的 ISP 图像信号处理单元还可以实时进行光线预测,最后加上新双摄和重新校准的传感器,让 AR 体验更加超乎想象的流畅体验,且真实感达到了前所未有的新高度。
A11 仿生只是苹果第一次自主设计 GPU 的尝试而已,虽然看起来是刚刚起步,但已经在 AR 方面发挥重大作用了,未来必然会往更重大的方向上前进。
毕竟苹果为了保持行业的差异化,多年期就开始部署自主基础技术,围绕处理器或传感器技术展开工作,目的是掌握更高的控制权,打造属于自己最理想的图形性能、创新视觉和图形环境。
神经网络引擎5 月份彭博社爆料苹果内部已经开始测试神经网络引擎,甚至是在搭载新 A 系列芯片的设备中测试,当时很多推测就认为 A11 非常有可能集成神经网络引擎。
事实证明,A11 仿生成为了苹果第一枚神经网络引擎的 SoC 移动 芯片。那么,这一神经网络引擎有什么呢?
苹果在发布会上解释,有一种 AI 人工智能叫作机器学习,即让电脑通过观察的方式进行学习。而神经网络引擎就是专为机器学习而开发的硬件,它不仅能执行神经网络所需的高速运算,而且具有杰出的能效。
简而言之,通过神经网络引擎能够担 CPU 和 GPU 的任务,大幅提升芯片的运算效率,以更少的能耗更快的完成更多任务。

在 A11 仿生中,苹果表示自家的神经网络引擎采用双核设计,每秒运算次数最高可达 6000 亿次。不过,苹果没有像华为那样透露具体的浮点运算性能(当时华为麒麟 970 的 NUP 在 FP16 下提供的运算性能可以达到 1.92 TFLOPs)。
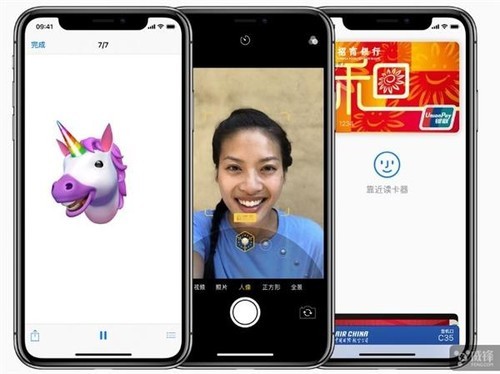
苹果表示,自家的 AI 单元主要用于胜任机器学习任务,能够识别人物、地点和物体,为“面容 ID”和“动话表情”等创新的功能提供强大的性能。
其中对于 iPhone X 的“面容 ID”,面容 ID 功能会投射 30000 多个肉眼不可见的红外光点,然后将得到的红外图像和点阵图案传输给神经网络,创建脸部的数学模型,再将这些数据发送至安全隔区,以确认数据是否匹配。而且,就算样貌随着时间而改变,它也能随之进行调整适应。

苹果A11深度详解:“仿生”可不是随便说说的
新闻 2021-04-28 16:06:07 
你知道QHD和1080p屏幕区别是什么嘛?别再傻傻分不清楚了
新闻 2021-04-28 14:47:14 
对标iPhone7!三星Note7国行版详尽评测:黑科技与时尚相结合的手机
新闻 2021-04-28 14:45:14 iPhone 11没有了3D Touch?但还有Taptic Engine
新闻 2021-04-28 14:43:33

问鼎销售冠军的iPhone5深度评测:撑起一个苹果时代的风骨
新闻 2021-04-28 14:38:54 GeForce Experience到底能干啥?多方面功能整合+优秀图形界面更方便
先锋影音资源畅享! 纽曼双卡音乐手机V300评测:一键管理资源方便快捷
新闻 2021-04-28 14:27:09

小米平板4评测:十分适合单手使用,游戏体验非常丝滑
新闻 2021-04-28 14:24:05 
安兔兔跑分天梯榜排行更新:iPhone依旧能打,稳居第一
新闻 2021-04-28 14:22:47 
全新Flyme 7对比Flyme 6 界面改变分析:样式更加简洁,视觉效果更加统一
新闻 2021-04-28 14:02:48 




 营业执照公示信息
营业执照公示信息
相关新闻